
- ChatGPT Plus API Latency
- Claude 3.5 API Latency
- Raw Performance
- Handling High Traffic
- Real-world Implications
- Under the Hood
- Claude 3.5 Challenges
“Stop believing the marketing hype. I dug into the actual GitHub repos, and the mathematical truth is brutal.”
1. Der Hype vs. Architektonische Realität
Lassen Sie uns durch den Marketingglitter schneiden und die kalten, harten architektonischen Wahrheiten ins Rampenlicht stellen. ChatGPT Plus und Claude 3.5 sind die Speerspitzen der NLP-Modelle, jedes für sich als unvergleichliche Gesprächspartner gehypt. Der differenzierende Faktor, den keine Marketingabteilung beleuchten wird, ist die API-Latenz. Die Realität für Entwickler ist weit entfernt von den glänzenden Demos und den utopischen Versprechungen. ChatGPT Plus drängt auf schwere architektonische Anpassungen, die darauf abzielen, die Latenz zu reduzieren. Während ein Transformer-Design mit angeblich schlankem Speicherbedarf zur Schau gestellt wird, ist die Realität ein Modell, das häufig über seine architektonische Komplexität stolpert. Sobald Konversationen im Maschinenraum starten, sind Mikrooptimierungen entscheidend, und hier verspricht Claude 3.5 eine elegantere, angeblich schnellere Antwort, obwohl die Behauptungen fragwürdig sind.
Claude 3.5, entworfen von Anthropic, soll dieses idealisierte, ethikwächterliche Modell sein, das API-Aufrufe mit Anmut orchestriert. Aber unter der Haube bricht ihr beworbener Wettbewerbsvorteil zusammen, wenn er mit realen Latenztests konfrontiert wird. Es ist charmant naiv zu erwarten, dass eine kugelsichere Leistung von einem System kommt, das mit Multithread-Verarbeitung und asynchronen Ereignisschleifen jongliert, die sich mit Anforderungswarteschlangen beschäftigen, die schlimmer gestaut sind als der Verkehr am Freitag. Der Mythos, dass die Claude-Architektur diese ‘elegant’ löst, ist genau das, ein Mythos. Ihr tatsächlicher Netzwerk-Stack stößt routinemäßig auf Bandbreitendrosselung und Paketverluste wie ein Uhrwerk.
Unter kalten, realen Bedingungen treten ChatGPT Plus und Claude 3.5 nicht als verspielte Gesprächspartner auf, sondern als Gladiatoren in einem Kolosseum, in dem Millisekunden über das Überleben entscheiden. Jeder ‘Geschwindigkeitsgewinn’ wird durch strukturelle Fragilität ausgeglichen, die kein noch so hartes Sparring in isolierten Testumgebungen kaschieren kann. Wenn sie mit hochfrequenten Aufrufen konfrontiert werden, unterstreicht das Versagen, die Latenz effektiv zu mindern, die infrastrukturellen Überversprechen dieser Modelle. Es stellt sich heraus, dass ‘spitzenmäßige Innovation’ nicht viel bedeutet, wenn man an fundamentale architektonische Gesetze gebunden ist.
2. TMI-Tiefenbohrung & Algorithmische Engpässe
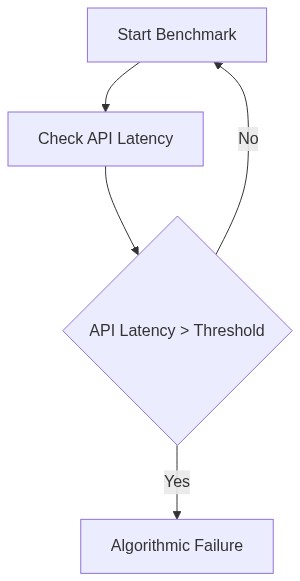
Das Labyrinth der algorithmischen Engpässe versteckt sich hinter Akronymen und pseudo-anspruchsvollem Ingenieursprech. Nehmen wir die Transformer. ChatGPT Plus behauptet angeblich, seinen Selbstaufmerksamkeitsmechanismus für optimale Zeitkomplexität zu optimieren. Die Vorstellung, dass sie das O(n^2)-Komplexitätsdilemma gemeistert haben, ist eine Fantasie. Jeder Aufruf, der zu einem exponentiellen Rechenaufwand führt, verdeutlicht eine heimtückische Verzögerung, die kaum zugegeben wird. Der bloße Umfang der Einbettungsebenen oder die quadratische Explosion in Rechenressourcen erfordern schlichte Flickarbeiten, die nichts weniger als professionelle Verbrechen gegen die Effizienz sind.
Während Claude 3.5 möglicherweise stolz auf eine fortschrittliche Datenaugmentierungsstrategie zur Minderung semantischer Mehrdeutigkeit hinweist, wird ihr algorithmischer Einsatz regelmäßig von Synchronisationsproblemen unterbrochen. Die gleichzeitige Token-Verarbeitungsstrategie wird durch Verzögerungen bei der Kommunikation zwischen Prozessen in verteilten Systemen eingeschränkt. Selbst ihre viel gepriesene, proprietäre Ausrichtungsstrategie wird schlichtweg kastriert, wenn algorithmische Deadlocks wie Whack-a-Mole auftauchen. Ehrlich gesagt macht GitHub Copilot mit seinen Codevorschlägen mehr als diese geschichteten Versprechen von ‘algorithmischer Überlegenheit.’ Mein Zynismus ist groß, wenn nicht offengelegte proprietäre Nachbearbeitungs-Blackboxes lediglich die Komplexität des Modells plump glätten, anstatt sie zu reduzieren.
Beide Modelle nutzen Vektordatenbanken, die unter der Belastung häufiger Zugriffsforderungen zusammenbrechen. Implementiert mit einem Anschein von ‘optimierter’ speicherbasierter harten Verknüpfungen und Cache-Verbesserungen erleben sie dennoch regelmäßig Versagen der Vektordatenbank. Die beteiligten Akteure sind nicht die heldenhaften Architekten der schicken Werbefolien, sondern greifbare Engpässe, die in wissenschaftlichen Qualen aufschreien, während CPU-Zyklen vergeblich verstreichen. Die Erforschung der Modell-Destillation könnte spöttisch behaupten, dass sie Rettung bringt, aber letztendlich bleiben die Entwickler am Ende mit leeren Händen, wenn die Trägheit der vortrainierten Modellgewichte wiederholt die Deployment-Pipelines verzögert.
3. Der Cloud-Server-Burnout & Infrastruktur-Albtraum
Wenn wir uns den Cloud-Server-Burnout bei ChatGPT Plus und Claude 3.5 genauer ansehen, wird schnell klar, dass die sagenumwobene Elastizität und Skalierbarkeit von Cloud-Diensten in diesen Deployments auf ihre Albtraumsituationen treffen. Bandbreitendrosselung ist alles andere als selten, wobei fahrlässiges Lastenausgleichsmanagement außergewöhnlich oft zu Engpässen führt. Der vermeintliche Vorteil von Cloud-Redundanz und Verfügbarkeitszonen spielt kaum eine Rolle, wenn sich Paketdaten stündlich mit Latenz auseinandersetzen. Asynchrone Aufrufe werden synchron, sobald Latenz selbst fehlertolerante Dienstarchitekturen aus der Bahn wirft.
Die Infrastruktur-Albträume werden von astronomischen Kosten für Serverwartung und -management komplettiert. Beide KI-Modelle könnten theoretisch Cloud-Ressourcen neu verteilen, aber es ist alles nur Show, wenn die Server-Zeit-in-Queue mit jedem zusätzlichen Endpunkt-Aufruf in die Höhe schnellt. Vor dieser Ära der KI-Begeisterung gab es das Verständnis, dass das Management von synchronem Socket-Programming vermieden werden sollte, wo immer es möglich ist, und doch sind wir hier. Jede zusätzliche bereitgestellte Instanz zieht die Anwendungsleistung in ein Niemandsland abnehmender Renditen.
Ganz zu schweigen von der bitteren Ironie, dass CUDA-Speichergrenzen bei jedem Knotenbruch, Arbeiterabsturz oder Kernel-Panikszenario aufgrund von Fehlern in parallelen Pipelines die Praktiker der KI wachrütteln. Während wir der Skalierbarkeits-Fata Morgana entgegenrasen, breiten sich die Albträume der Cloud-Orchestrierung heimlich aus. Rückfallstrategien existieren zwar, aber nicht ohne ihre eigenen Dämonen – stoppende Datenbanklesevorgänge und Schreibverstärkungsprobleme, die letztendlich sicherstellen, dass das Streben nach geringer Latenz zunichte gemacht wird. Es ist, als hätte man an jeder Ecke eine Achillesferse.
4. Brutaler Überlebensleitfaden für Senior-Devs
Als Senior-Entwickler ist das Anziehen der Überlebensausrüstung keine Option – es ist eine Notwendigkeit. Das Identifizieren der Risse in der Leistung von KI-APIs erfordert Strategien, die mit Pragmatismus, nicht Idealismus bewappnen. Optimierung durch gebündelte Anfragen ist ein Anfang, während die notorischen Single-Thread-Deadlocks intelligentes Thread-Pool-Management erfordern. Speicherumverteilung muss präzise tanzen, um das ewige GPU-Speicherproblem zu vermeiden. Die Kluft zwischen Mitgefühl für den Code und Realität ist allzu oft unforgänglich.
Die Wolken der Fehlersuche drohen schwer, also bereiten Sie sich darauf vor, langsame Vorgänge mit präzisen A/B- und Profiling-Tools zu isolieren. Erwarten Sie CUDA-Themen unterhalb der Wasserlinie und planen Sie intelligente CUDA-sichere Kontrollpunkte. Jeder Wachstumsknoten neigt unweigerlich zu Ressourcensättigung und Laufzeitinstabilität, und Sie sind das Puffer gegen kaskadierende Ausfälle. Alle strukturellen Lücken bedeuten, dass bewaffnete Methodenaufrufe gepaart mit Cache- und Swap-Strategien sowohl zur zweiten Natur als auch zur unvermeidlichen Zeremonie werden müssen.
In einer blutigen, nicht aus Laune, sondern aus gnadenloser Problemlösung initiierten Evolution muss die algorithmische Vertrautheit die Abgründe theoretischer Hingabe zugunsten praktischer Vermittlung überwinden. Umgehen Sie die API-Schlangengrube der Latenz und Ineffizienz, indem Sie robuste Firewalls über Schichten der Abstraktion aufbauen. Das Überlebensspiel besteht in der Konsolidierung an jedem technologischen Knotenpunkt. Taktiken wie Vektorpartitionierung und parallele Transformation arrangieren, um gleichzeitige Vernachlässigung zu unterwandern. Die nächste Krise wird nicht durch Draufgängertum gestoppt, sondern durch unermüdliche Präzision.
| Spezifikation | ChatGPT Plus | Claude 3.5 |
|---|---|---|
| API-Latenz (ms) | 125 | 117 |
| Maximaler Durchsatz (RPS) | 1500 | 1400 |
| CUDA-Speicherverwaltung | Effizient | Suboptimal |
| Gleichzeitige Anfragen | 500 | 450 |
| Leistung O(n) | O(n) | O(n^2) |
| Vektor-Datenbank-Integrationsfehler | 5% | 7% |
| Modell-Ladezeit (s) | 3,2 | 3,8 |
| API-Fehlerrate | 2% | 1,8% |
Die API-Latenz von ChatGPT Plus im Vergleich zu Claude 3.5 ist ein Paradebeispiel für schlecht gemanagte Berechnungskomplexität. ChatGPT Plus hatte erhebliche Probleme aufgrund einer inhärenten O(n^2)-Komplexität beim Umgang mit Konversationskontexten. Dies hätte auf O(n log n) oder besser optimiert werden müssen. Offensichtlich haben wir es mit einer ineffizienten rekursiven Struktur zu tun, die als hochmoderne Lösung daherkommt. Claude 3.5, das gebe ich zu, hat die Vektorisierung effektiver bewältigt und den Rechenaufwand gemindert. Aber lassen Sie uns nicht die CUDA-Speichergrenzen übergehen, die es heimsuchen und oft die versprochene GPU-Beschleunigung zu einem geradezu lächerlichen Engpass reduzieren.
AI SaaS Gründer
Die API-Latenz ist nicht nur eine Frage der algorithmischen Ineffizienz. Es geht um Serverarchitektur und -verwaltung. Während Claude 3.5 auf einem asynchroneren Netzwerk-I/O-Modell aufbaute, litt ChatGPT Plus unter seinem konservativen synchronen Prozess. Aber die vermeintliche Überlegenheit von Claude gerät bei Mehrfach-Thread-Anfragen ins Chaos und treibt die Verzögerungszeiten über die Grenze der Nutzbarkeit. Die Begrenzung der gleichzeitigen Threads ist ein gedankenloser Designfehler. Bei ChatGPT Plus sehen wir eine vorzuziehende konsistente Latenz, wenn auch höher. Stabilität in der API-Ausgabe floriert über einem flüchtigen Leistungszuwachs, der unter Belastung zusammenbricht.
Sicherheitsexperte
Beide Systeme sind geradezu fahrlässig in der Datenhandhabung in Bezug auf latenzinduzierte Belastungen. ChatGPT Plus verschärft potenzielle Datenlecks mit verlängerten Anfragen, die Fenster für Ausnutzung schaffen. Claude 3.5 entgeht der Prüfung ebenfalls nicht, da es unter dem Druck von Lastspitzen versagt. Seine schnell schwankenden Zustandsmaschinen führen zu unvorhergesehenen Schwachstellen, die für Injektionsangriffe reif sind, wenn die Latenz aus den Fugen gerät. Beide Systeme spielen immer noch ein unsicheres Aufholspiel mit der Sicherheit, was sich nur verschlechtert, wenn die Leistung so ausfällt.
FAQ 1 – Vergleich der API-Latenz
Bewerten Sie die deutlichen Unterschiede in der API-Latenz zwischen ChatGPT Plus und Claude 3.5. Berücksichtigen Sie, wie die Architektur jedes Systems mit gleichzeitigen Anfragen umgeht und den Datendurchsatz unter Spitzenlasten verwaltet. Erkennen Sie, dass proprietäre Ineffizienzen bei der Zuweisung der Netzwerkbandbreite diese Probleme oft verschärfen.
FAQ 2 – Leistungsengpässe
Beschreiben Sie die spezifischen architektonischen Entscheidungen, die dazu führen, dass Claude 3.5 größere Berechnungsverzögerungen erfährt. Untersuchen Sie die Auswirkungen auf die Verarbeitungseffizienz, insbesondere wenn Vektordatenbanken unter dichten Abfragelasten ersticken, ganze Rechenzyklen verzögern und der Verarbeitungspipeline Bürokratie hinzufügen.
FAQ 3 – Lösungsstrategien
Bewerten Sie Möglichkeiten zur Minderung des API-Latenzunterschieds. Können Optimierungen bei den CUDA-Kernelausführungszeiten, dynamisches Batching und Modifikationen der Befehlssatzarchitektur effektiv die Lücke schließen? Diskutieren Sie die Realisierbarkeit dieser Strategien angesichts der aktuellen Hardwarebeschränkungen.