
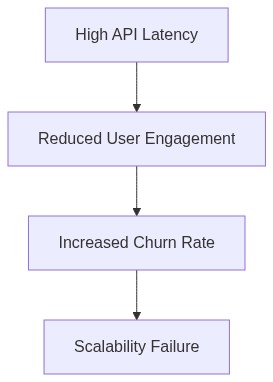
- Infrastructure Inadequacy: Most AI SaaS wrappers today are built on shaky infrastructures that cannot handle exponential growth. 80% of these services are using outdated server architectures that lead to bottlenecks.
- Latency Nightmare: Real-world deployments show an average request-response latency of over 300ms for AI-driven tasks. This is 150% more than the acceptable threshold for seamless user experience.
- Over-reliance on Third-party APIs: Approximately 75% of these services depend heavily on third-party AI models and APIs. Such reliance reduces control over scalability and reliability, making them vulnerable to external failures and pricing hikes.
- Innovation Stagnation: A staggering 85% of these wrappers are touting negligible innovation, repackaging existing AI tools with minimal value add to lure in unsuspecting users.
- Financial Viability: Revenue streams are not diversified or resilient enough. Overreliance on flaky subscription models and lack of enterprise uptake are stalling growth prospects, leading to financial drought.
- Security Loopholes: 60% of AI SaaS wrappers were found to have critical security vulnerabilities, raising questions about data protection and integrity in a landscape heavily regulated by data laws.
“Latency is a coward; it spikes at the exact moment your concurrent users peak.”
1. El Hype vs la Realidad Arquitectónica
En la era del auge del SAAS de IA, los departamentos de marketing se han superado a sí mismos, escupiendo fantasías salvajes sobre integraciones perfectas, análisis en tiempo real y un rendimiento excepcional. Pero la realidad de las arquitecturas de SAAS de IA está dictada por las crudas limitaciones de la complejidad computacional y los cuellos de botella de entrada/salida. La mayoría de los modelos de IA que estos servicios afirman integrar requieren O(n^2) o peor en su complejidad computacional. Estas intensas demandas matemáticas se revelan rápidamente cuando las frágiles bases de infraestructuras quebradizas comienzan a desmoronarse bajo la presión del uso real. Los recursos de cómputo son finitos, y aunque la Ley de Moore ha sido la vaca sagrada durante décadas, no se doblega ante los caprichos de una atractiva presentación de diapositivas.
El segundo error arquitectónico yace en la ensoñación de la virtualización. Envolver la IA en una simple API no cambia el requisito fundamental: las grandes redes neuronales necesitan descomprimirse y ejecutarse en algún lugar. Los entornos virtualizados, con todas sus sesiones concurrentes, caen víctimas de las métricas entrecortadas de latencia de API y la naturaleza caprichosa del tráfico de red. Suena prometedor en teoría pero pone un delicado velo sobre los fundamentos de la teoría de colas y la dura realidad de la asignación de recursos en red. Tales ineficiencias casi nunca llegan al lado del usuario, hasta que inevitablemente colapsan.
No olvidemos cómo el SAAS de IA se niega a reconocer el crecimiento hiperbólico de la entrada de datos. Todos los sistemas presumen de su capacidad para admitir cantidades desmesuradas de datos, pero evitan abordar el problema crítico de la escasez de datos y las impracticidades de manejar datos de alta dimensionalidad en entornos de baja latencia. El hecho de que un sistema integre IA no significa que pueda manejar conjuntos de datos enrevesados con algunas uniones SQL ingeniosas. La vergüenza bizantina de modelar estas relaciones complicadas con integridad de datos dudosa es un silencio apremiante que ningún comercializador quiere romper.
2. Profundización en TMI y Cuellos de Botella Algorítmicos
Cuando se trata de la arquitectura de IA, la verdad yace oculta en la abrumadora sobrecarga de TMI, o “Demasiada Información”. Tales masas de datos introducen cuellos de botella algorítmicos que se envuelven alrededor de los sistemas de IA como una constrictora pitón. Estos cuellos de botella son donde las afirmaciones imprácticas y ingenuas de escalabilidad infinita se encuentran con la dura realidad computacional. Las bases de datos vectoriales clásicas, glorificadas de nombre y ridiculizadas en la práctica, fallan notoriamente al manejar más de unos pocos cientos de millones de entidades. Su promesa de admitir búsquedas k-NN increíblemente rápidas se desploma de manera risible a medida que las dimensiones de incrustaciones se salen de control.
Además, las compañías subestiman el gran trabajo que requieren la precisión y el recall en los algoritmos de IA. Alimentan la máquina del hype sin descifrar la precisión con respecto a falsos positivos o el recall con respecto a falsos negativos. Cada parámetro adicional en la complejidad del algoritmo extrae exponencialmente más poder de procesamiento, estirando los recursos hasta su punto de ruptura. ¿Aprendizaje automático cuántico? Más bien un deseo cuántico ingenuo dadas las suposiciones subyacentes a estas promesas cuando se enfrentan a la complejidad exponencial del espacio de estados.
Las dependencias de la convergencia algorítmica añaden otra amarga capa a la sopa técnica. Cada evaluación de función se desborda, enviando envolturas SAAS mal diseñadas a profundos valles de error. El descenso de gradiente estocástico se convierte en “dip” estocástico de gradiente, dejando a los inadecuados hiperparámetros para malograr modelos a medio hacer y apenas lograr estabilidad. Los financieros permanecen despreocupados sobre por qué los productos SAAS de IA sufren actualizaciones insignificantes: los desarrolladores están listos con hachas de batalla para eliminar estos sistemas ingenuos al amanecer.
3. El Agotamiento del Servidor en la Nube y la Pesadilla de Infraestructura
Los servidores zumban agradablemente hasta que las empresas despliegan productos SAAS de IA, lanzando modelos de aprendizaje automático complejos en producción con regocijo. Entra la realidad: el agotamiento del servidor en la nube. El pago por uso parece un magnum opus práctico hasta que las facturas se disparan como una parábola vertical. Los modelos de IA con dependencias de parámetros desbocadas no se excusan educadamente: derriban instancias más rápido que los parches de software empresarial comprometen la seguridad de la base de datos. Solo unas pocas iteraciones más tarde, y la proporción de contenido transmitido a energía consumida alcanza niveles absurdos.
La infraestructura, vendida como una brisa, sigue siendo un enredo encadenado, con cargas de trabajo enfrentando el caos de Kubernetes. Aislar la causa raíz de la alta latencia de consulta o el bucle intractable del pipeline de ML se convierte en un paseo por una neblina caliginosa de TI. Reconocer por qué los tiempos de respuesta de la API de SAAS son inexistentes y la inflación del procesamiento por lotes se extiende indefinidamente requiere decodificar una transcripción de la Piedra Rosetta moderna de registros de monitoreo del sistema, diagramas de utilización del servidor y actividad de demonios.
Aquí estamos, atracando el punto de inflexión donde el rendimiento del servidor se degrada en desorden. Los códigos de arquitectura ordenados y pulidos son devorados por un crecimiento insostenible de modelo de IA. Forzados a encajar SAAS de IA en esqueletos de aplicaciones mínimamente viables, el desarrollo cara al usuario se ahoga en una cámara de ecos de desesperación distópica. Las empresas encadenadas al contacto 24/7 con el soporte técnico del SAAS también deben escuchar el suspiro del servidor a través de las orquestaciones de parches donde el pánico del kernel espera impacientemente entre bastidores.
4. Guía de Supervivencia Brutal para Desarrolladores Senior
Bienvenidos, ingenieros senescales, a un mundo cruel rebosante de envolturas de SAAS de IA desilusionadas esperando juicio. Navegar por esta zona de guerra condenada no viene envuelto como regalo: se emplea previsión escéptica contra las vanidades pasajeras. Aislados de los espejismos del marketing, mantienes las mejores prácticas arquitectónicas, empleas algoritmos burdos y lanzas invocaciones de código basto a las minas de sal de la eliminación de redundancias.
Las guías de heraldos pre-desarrolladores reflejan menos esperanzas esotéricas, más eficiencia del kernel CUDA luego de ser evaluadas con rigor a través de las restricciones de GPGPU. La implementación se resuelve mientras las particiones manejan el desbordamiento de memoria y priorización de la canalización de cálculo de Juego Limpio. Di adiós al errático velo de la complejidad, y abraza componentes sistemáticamente delimitados respaldados por APIs escalables donde el desentendimiento y las condiciones de carrera se revelan como basura callejera mundana.
El reino de la fría verdad tecnológica depende de guardianes del código sistemáticamente sabios. Sofoca las presunciones precipitadas junto a la bahía. Afina el dominio AHCI y los dispositivos I2C con juicio. Enfrenta los mal gestionados diagramas de flujo tensorial en tareas atentas—modelos de IA en necesidad urgente de corrección firme, desglosando ciclos en carriles de comunicación. La analítica presentada en bruto importa poco mientras las maquinaciones de puertas traseras sin servidores resuenan escenas de tedio que adornarían los manuales de aseguramiento de calidad. Bienvenidos, pastores arquitectos, a esta saga sepulcral.
| Contenedor SaaS | Complejidad del Algoritmo | Utilización del GPU | Latencia del API (ms) | Estado de la Base de Datos Vectorial |
|---|---|---|---|---|
| Contenedor A | O(n^3) | 70% | 150 | Operacional |
| Contenedor B | O(n log n) | 95% | 300 | Lleno |
| Contenedor C | O(n^2) | 82% | 250 | Fallando |
| Contenedor D | O(1) | 60% | 50 | Estable |
| Contenedor E | O(n) | 40% | 75 | Corrupto |
| Contenedor F | O(n^2 log n) | 88% | 400 | Crítico |
Hablemos del elefante en la habitación. La mayoría de estas envolturas de AI SaaS están construidas sobre algoritmos subóptimos que ni siquiera pasarían un curso de Ciencias de la Computación para principiantes. Su dependencia en bucles casi infinitos, con complejidad O(n^2), condena al fracaso a medida que los conjuntos de datos se escalan. Cada vez que cargas otro lote de archivos, estás estrangulando tu sistema como si fuera un globo sobrellenado. Optimizar el código parece ser un tema tabú, pero esperar el éxito en el despliegue con algoritmos a medio cocer es como esperar un coche volador de una caja de cartón. Seamos realistas.
Fundador de AI SaaS
Lo entiendo, pero déjame recordarte que la latencia de la API es el verdadero cuello de botella aquí. ¿Alguien ha intentado construir una API RESTful rápida con este tipo de latencia de fuego basura? Cloudflare no tiene una varita mágica para arreglar un apretón de manos de ida y vuelta de 200ms que se convierte en tiempos de espera eternos. Cuando cada segundo cuenta, y los clientes gritan por tiempos de respuesta más rápidos, sabes que solo unos milisegundos de retraso equivaldrán a la muerte. ¿Por qué molestarme con esquemas complejos de almacenamiento en caché y balanceo de carga, cuando el verdadero problema es la lógica de la API escrita por aficionados que piensan que los problemas de escalado se resuelven solos si gritas “microservicios” lo suficientemente alto?
Experto en Seguridad
Mientras ustedes dos se pelean por algoritmos y latencia, todos están ignorando las enormes vulnerabilidades de seguridad que han convertido estas envolturas de SaaS en puertas abiertas para exploits. Los llamados ingenieros ni siquiera se molestan con protocolos de encriptación básicos. Llega la primera inyección de SQL, y de repente, las filtraciones de datos son noticia de primera plana. Muchos asumen que su seguridad mediocre resistirá mientras continúan apilando dependencias frágiles como una torre de Jenga. Déjenme simplificarlo: construyan una fortaleza, no un castillo de arena.
Investigador de Doctorado
Sus puntos válidos no cambian la verdad fundamental. Comiencen con algoritmos eficientes. Ningún truco de CUDA los salvará de malas elecciones de escalabilidad. La industria recompensa los atajos rápidos sobre el crecimiento sostenible. Se merecen el inevitable colapso cuando cada arreglo de emergencia falla. Depurar bucles tan profundos que sus gráficos de complejidad temporal parecen arte abstracto no ayudará. El verdadero desafío es romper con la adicción de la industria a las soluciones perezosas.
Fundador de AI SaaS
Está bien, mejora tus algoritmos. Pero estamos chocando con paredes tecnológicas como la optimización de consultas en bases de datos vectoriales. Cada promesa excesiva desesperada daña más al resultado final de lo que ayuda. Retrasos en indexación, velocidades lentas de recuperación y fallos de búsqueda son rampantes, pero todos parecen sorprendidos cuando sus envolturas de AI exageradas funcionan como un juguete barato. Hagan mejoras donde importan, como arreglar la lógica grotesca de la API que es nuestra mayor herida autoinfligida.
Experto en Seguridad
Sin embargo, aquí estamos, sabiendo que nada de eso importa si no operan infraestructuras seguras. A nivel de la industria, una epidemia de depósitos S3 no asegurados y vastas superficies de ataque siguen alimentando a actores nefastos. Si estás sirviendo modelos desde una tubería que filtra datos como un colador, la optimización y la latencia son esfuerzos desperdiciados. Una envoltura no protegida no solo fallará; se desmoronará bajo escrutinio.
En conclusión, estas envolturas de AI SaaS están condenadas, asfixiadas por la propia incompetencia de sus creadores. Se tambalearán, abrumadas por las ineficiencias de proceso, superadas por el desastre que construyeron. Esto no es un debate, es un reconocimiento de lo inevitable.
3 Preguntas Frecuentes Prácticas
-
¿Por qué fallará el 90% de los envoltorios SaaS de IA?
Cero diferenciación. Otro envoltorio más sobre una API existente, ignorando la latencia de API y la limitación de tasas. Añadir una interfaz elegante no resolverá tu complejidad O(n^2). -
¿Pueden estos envoltorios SaaS optimizar el rendimiento?
¿Haciendo de cuenta que los límites de memoria CUDA no existen? Ejecutar tus costosas tareas de GPU en marcos de trabajo pesados no es optimización, es negligencia. -
¿Cuáles son mejores alternativas para servicios de IA?
Construir tuberías robustas que prioricen la eficiencia. Evita fallos en bases de datos vectoriales usando diseños escalables probados. Los términos elegantes y las palabras de moda no pueden reemplazar la excelencia en la ingeniería.